Kapitel 1 Einleitung
In diesem Kapitel wird die allgemeine Herangehensweise an die verschiedenen Themen dieses Buches erläutert. Außerdem werden hilfreiche Bücher zur Vertiefung und zum Erlangen eines besseren Statistikverständnisses vorgestellt.
1.1 Für wen ist dieses Buch?
Das Buch ist grundsätzlich für jeden und jede geeignet, der oder die R lernen möchte. Vorwissen über Programmiersprachen wird nicht vorausgesetzt. Neben den Grundlagen von R wirst du nach Lesen dieses Buches in der Lage sein, einen Datensatz einzulesen und zu bereinigen. Du wirst verstehen, wie man publikationsreife Visualisierungen und Tabellen erstellt. Auch wirst du deskriptive Maße und die gängigsten statistischen Hypothesentests berechnen können. Die statistischen Verfahren werden nicht separat eingeführt, da es dafür bereits ausführliche Lehrbücher gibt. Dieses Buch konzentriert sich folglich auf die computergestützte Datenauswertung und nicht auf die zugrundeliegende Statistik.
1.2 Aufbau und Bearbeitungsstrategie
Die Kapitel sind in der Reihenfolge aufgebaut, wie man normalerweise mit einem frisch erhobenen Datensatz umgeht. Nachdem alles korrekt eingerichtet und aufgesetzt ist (Teil I), werden die Daten bereinigt und aufbereitet (Teil II), bis die Fragestellungen mithilfe statistischer Analysen beantwortet werden (Teil III). Vertiefende Konzepte für eine fortgeschrittene Verwendung runden den Inhalt des Buches schließlich ab (Teil IV).
Teil I: Die ersten Schritte. Kapitel eins und zwei bilden den ersten Teil, der auch von LeserInnen, die bereits mit R gearbeitet haben, gründlich durchgelesen werden sollte. Vor allem die Installation stellt häufig schon die ersten Hürde dar. Es werden außerdem verschiedene Hilfestellungen eingeführt.
Teil II: Vorbereitung. Die meiste Zeit in der Datenanalyse wird für die Datenvorbereitung benötigt. Die eigentliche Auswertung geht anschließend meistens vergleichsweise schnell. Daher ist die Datenvorbereitung auch eines der umfangreichsten Kapitel dieses Buches. Zusätzlich werden die essentiellen R-Projektdateien sowie einige notwendige Grundlagen erläutert. Darüber hinaus wird das Einlesen von Datensätzen unterschiedlicher Dateiformate erklärt.
Teil III: Auswertung. Wenn der Datensatz endlich fertig aufbereitet ist, können Abbildungen erstellt sowie deskriptive Statistiken und inferenzstatistische Hypothesentests berechnet werden. Die Visualisierungen und in Tabellen dargestellten Ergebnisse werden dabei direkt publikationsreif ausgegeben.
Teil IV: Vertiefung. Hier werden weiterführende und vertiefende Konzepte vorgestellt, die nicht zwingend für die eigentliche Datenanalyse benötigt werden. Du wirst lernen, wie man Tabellen oder ganze Berichte in Word oder PDF umwandeln kann. Die verschiedenen Datenstrukturen werden verglichen und abschließend fortgeschrittenere Programmiertechniken vorgestellt.
Jeder und jede hat einen individuellen Lernstil und liest ein Lehrbuch auf unterschiedliche Weise. Die einzelnen Kapitel des Buches bauen zwar grundsätzlich aufeinander auf, dennoch wurde darauf geachtet, die Kapitel zum schnellen Nachschlagen möglichst in sich geschlossen zu halten. Wer also nicht das gesamte Buch Schritt für Schritt durcharbeiten möchte, sollte zumindest nachfolgend empfohlene Kapitel gelesen haben. Dies gilt auch für jene, die beispielsweise nur an einem ganz bestimmten statistischen Hypothesentest für die Bachelorarbeit interessiert sind.
Zeitmangel? Du solltest dich mindestens mit den Kapiteln 2, 3, 4, 5 und 6.1 vertraut machen, da diese essentiell zum Arbeiten mit R sind.
1.3 Boxen, Übungen und Datensätze
In diesem Buch gibt es drei Arten von Boxen in jeweils unterschiedlicher Farbe und jeweils eigenem Symbol. Die mit der Glühbirne markierten Boxen heben besonders wichtige Konzepte des Kapitels hervor. Die Boxen mit dem Warnzeichen weisen auf häufige Probleme hin und die Boxen mit dem Laptop beschreiben interaktive Übungen. Beispiele für diese Boxen könnten wie folgt aussehen:
Nach Durcharbeiten dieses Buches kann jeder und jede selbstständig Fragestellungen verschiedener wissenschaftlicher Fachrichtungen anhand eigener Datensätze beantworten.
Nach dem Starten von R sollte immer zuerst ein Projekt erstellt werden, bevor die Datensätze durch Befehle innerhalb eines R-Skripts eingelesen werden.
Übung 4.3.1. Das Verstehen der Grunddatentypen ist zum Arbeiten mit R essentiell. In dieser Übung wird das Verständnis mithilfe allgemeiner Fragen und anhand einer Nutzerstatistik eines Musikstreamingdienstes geprüft. Besonders werden zudem die logischen Datentypen wiederholt. Starte die Übung mit uebung_starten("4-3-1") (siehe Kapitel 1.3).
Für ausgewählte Kapitel gibt es interaktive Übungen, die auf deinem Computer lokal gestartet werden. Der Fortschritt, den du bei diesen Übungen machst, wird gespeichert. So kannst du später an der Übung weiterarbeiten. Bei größeren Updates der Übungen (z.B. nach Fehlerbehebungen) kann es allerdings passieren, dass du die Übung von vorne beginnen musst.
In Abbildung 1.1 ist exemplarisch eine Übung aus Kapitel 4.3.1 gezeigt. Auf der linken Seite ist eine Navigationsleiste, in der verschiedene Unterkapitel der Übung angezeigt werden, zwischen denen man wechseln kann. Darunter können die Fortschritte der Übung mit Neustart zurückgesetzt werden. Dein Wissen aus den Kapiteln wird im Regelfall über Single-Choice oder Multiple-Choice Fragen abgefragt. Dabei werden teilweise Eingabefelder für deinen Code bereitgestellt, um verschiedene Dinge vor Beantwortung der Fragen auszuprobieren. Über dem Eingabefeld kann mit Neustart der Inhalt des Feldes gelöscht werden. Daneben gibt es den Button Tipps, welcher dir bei Bedarf Hinweise über die zu verwendende Funktion liefert. Schließlich kannst du den Code über den Button Code ausführen ausführen.
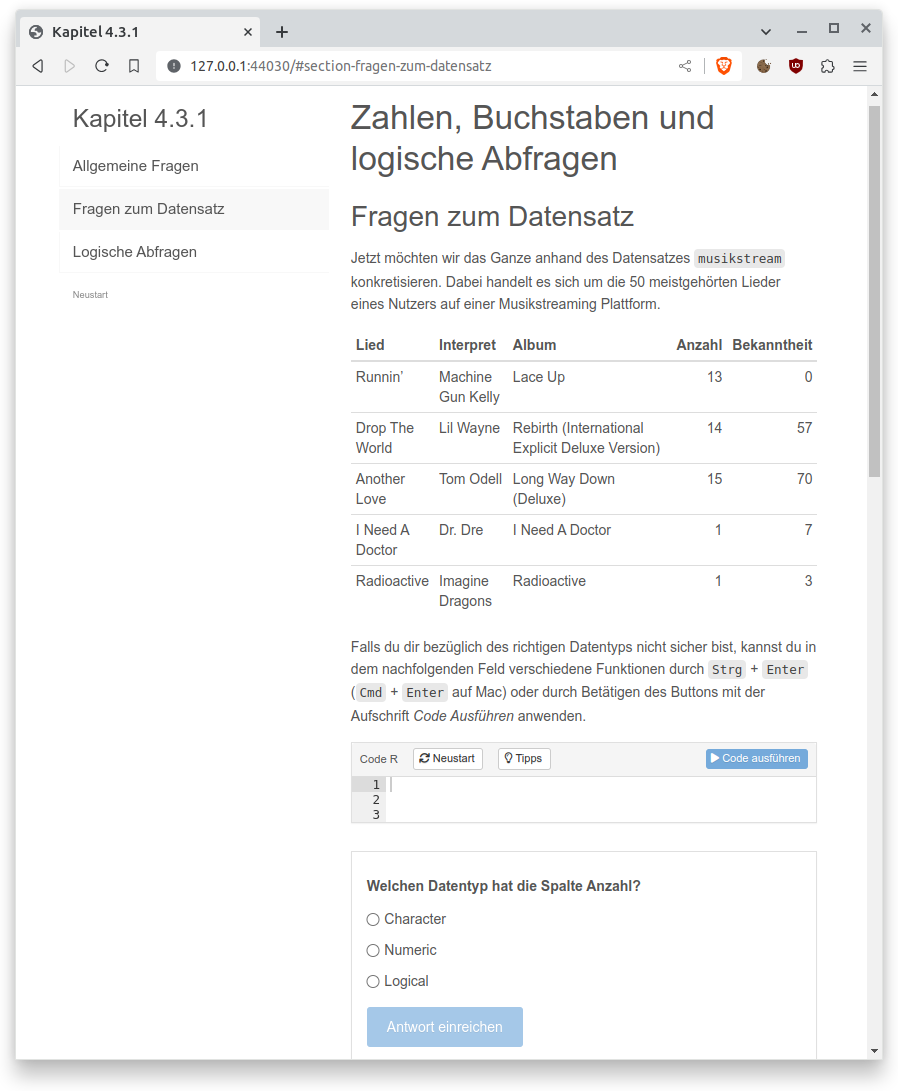
Abbildung 1.1: Beispiel einer interaktiven Übung.
Alle vorhandenen Übungen können mit uebung_anzeigen() ausgegeben werden. Eine Übung wird mit der Funktion uebung_starten() und derder Kapitelnummer in Klammern gestartet. Was genau eine Funktion ist und wo diese auf welche Art ausgeführt werden muss, wirst du in Kapitel 2.2 und 2.4 lernen. Beachte, dass zum Ausführen der Übungen eine Erweiterung namens learnr installiert sein muss (siehe Kapitel 2.5.2).
Dies ist ein Beispiel für einen Codeblock. In diesem Buch werden viele konkrete Codebeispiele zum Erlernen der verschiedenen Konzepte verwendet, die immer grau hinterlegt sind. Wenn du in der Online-Version deine Maus über diesen Codeblock bewegst, erscheint auf der rechten Seite ein Button mit zwei Dokumenten. Durch Klicken dieses Buttons wird der Code des Blocks gespeichert und du kannst ihn für deine Zwecke verwenden. Alternativ kannst du auch den Code markieren und mit Strg + c bzw. Rechtsklick + Kopieren kopieren oder den Code händisch abtippen.
Begleitend zum Buch werden zudem 19 Datensätze bereitgestellt, die im Appendix und im Internet unter https://r-empirische-wissenschaften.de/reference/index.html vorgestellt werden. Während ein Teil der Datensätze direkt im Buch verwendet wird, wirst du mit anderen nur in den Übungen konfrontiert werden.
1.4 Ergänzende Literatur
Statistik-Grundwissen: In diesem Buch wird in Kapitel 9 die Umsetzung statistischer Modelle nach der frequentistischen Inferenzstatistik in R gezeigt. Für die statistischen Grundlagen empfehlen sich die Bücher Statistik: Der Weg zur Datenanalyse und Regression Methods in Biostatistics: Linear, Logistic, Survival, and Repeated Measures Models (Fahrmeir et al., 2016; Vittinghoff et al., 2012).
Auf die Realisierung bayesianischer Methoden in R wird im Rahmen dieses Buches nicht eingegangen, da diese bereits in Statistical Rethinking umfassend vorgestellt werden (McElreath, 2020).
Verfahren für kausale Schlussfolgerungen werden hier ebenfalls nicht verwendet. Für die mathematischen Grundlagen sei auf Causal Inference: What if und Causal Inference: The Mixtape verwiesen (Hernán & Robins, 2020; Cunningham, 2021). Die programmatische Umsetzung der entsprechenden Ansätze wird ausführlich in Causal Inference in R beschrieben.
Vertiefung in R: In Kapitel 10 wirst du lernen, wie man die Ergebnisse aus R direkt in ein Word oder PDF Dokument umwandelt. Die Anpassungsmöglichkeiten für das Aussehen der entsprechenden Dateien sind vielfältig. Während du die Grundlagen zwar hier kennenlernen wirst, stellt das Buch R Markdown: The Definite Guide ein umfangreiches Nachschlagewerk zur Erstellung komplexerer Dokumente dar (Xie, Allaire & Grolemund, 2018).
Falls du einen Schritt weitergehen möchtest und an der Programmierung mit R interessiert bist, solltest du im Anschluss das Buch Advanced R durchlesen (Wickham, 2019).